ilert ist die Incident-Management-Lösung, die von Grund auf als Single-Application konzipiert wurde und den gesamten Lebenszyklus der Reaktion auf Vorfälle abdeckt.
Die Funktionen, die Sie für den Betrieb von Always-On-Services benötigen
Jede Funktion in ilert wurde entwickelt, um Ihnen zu helfen, schneller auf Vorfälle zu reagieren und die Verfügbarkeit zu erhöhen.
Nutzen Sie das Potenzial generativer AI
Verbessern Sie die Kommunikation bei Vorfällen und optimieren Sie die Erstellung von Post Mortems mit ilert AI. ilert AI unterstützt Ihr Unternehmen dabei, schneller auf Vorfälle zu reagieren.
ilert stellt mithilfe unserer vorgefertigten Integrationen oder per E-Mail eine nahtlose Verbindung zu Ihren Tools her. Ilert lässt sich in Überwachungs-, Ticketing-, Chat- und Kollaborationstools integrieren.
So erreichen führende Unternehmen mit ilert eine Uptime von 99,9 %
Unternehmen weltweit vertrauen auf ilert, um ihr Incident-Management zu optimieren, die Zuverlässigkeit zu steigern und Ausfallzeiten zu minimieren. Lesen Sie, was unsere Kunden über ihre Erfahrungen mit unserer Plattform sagen.
Erfahren Sie, wie Sie Zabbix Cloud für AWS Auto-Discovery einrichten und kritische Alarme per SMS, Anruf oder Push-Benachrichtigung erhalten.
Beim letzten Zabbix Summit stellte das Unternehmen eine Cloud-Version seiner bekannten Monitoring-Plattform vor. Wir bei ilert beobachten stetig die wachsende Beliebtheit von Zabbix, da immer mehr Teams weltweit die Lösung für ihre Monitoring-Anforderungen einsetzen. Um Nutzer:innen bei der schnellen Einführung der neuen Cloud-Version zu unterstützen, haben wir diesen Leitfaden erstellt.
Warum Zabbix
Die Sicherstellung der Betriebsfähigkeit und Stabilität von Cloud-Infrastrukturen wie Servern, virtuellen Maschinen, Datenbanken, Containern und Anwendungen aufrechtzuerhalten, ist für Unternehmen jeder Größe essenziell. Zabbix Cloud Monitoring ist ein effektives Tool, um all diese Ressourcen bei bekannten Cloud-Anbietern wie Google Cloud Platform (GCP), Microsoft Azure und Amazon Web Services (AWS) im Blick zu behalten.
Zabbix Cloud Monitoring bietet Unternehmen proaktives Alarmmanagement, automatische Anomalieerkennung und Echtzeit-Einblicke in ihre Cloud-Infrastruktur. Im Gegensatz zu klassischen Monitoring-Lösungen kombiniert Zabbix agentenbasierte und agentenlose Techniken, um wichtige Leistungskennzahlen zu überwachen, Probleme frühzeitig zu erkennen und eine optimale Systemleistung sicherzustellen.
Was dieser Leitfaden abdeckt
Dieser Schritt-für-Schritt-Leitfaden hilft Ihnen dabei:
Zabbix Cloud Monitoring für AWS Auto-Discovery einzurichten und zu konfigurieren;
Cloud-Dienste mit hilfe von API-basierten Monitoring zu integrieren – für vollständige Transparenz;
Dashboards zu erstellen, um Ihre Infrastruktur proaktiv zu verwalten;
Kritische Zabbix-Alarme über verschiedene Kanäle wie SMS, Anruf, Messenger oder Push-Benachrichtigung mit hilfe von ilert zu empfangen.
Voraussetzungen: Was Sie für diesen Leitfaden brauchen
Eine bereitgestellte Zabbix Cloud Instanz, die über den Browser erreichbar ist;
Ein AWS-Konto mit API-Zugriff;
IAM (Identity and Access Management) Policy: Du musst eine IAM-Richtlinie für eine Zabbix-Rolle in deinem AWS-Konto mit den entsprechenden Berechtigungen erstellen;
CloudWatch-Metriken: Stelle sicher, dass CloudWatch-Metriken für Ihre AWS-Ressourcen wie EC2-Instanzen, RDS-Datenbanken und S3-Buckets aktiviert sind, um Monitoring-Daten bereitzustellen.
Teil 1: Erstellen einer IAM-Richtlinie für Zabbix
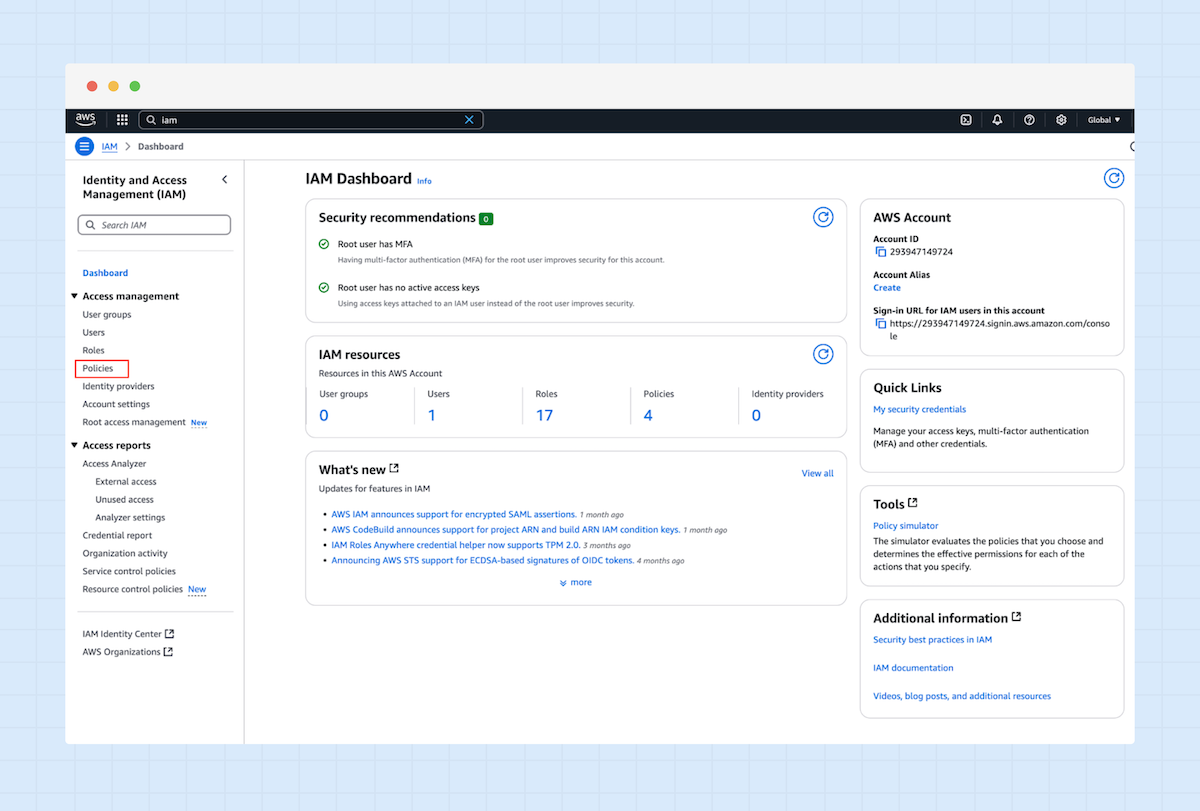
1. Öffnen Sie in AWS den IAM-Service und klicken auf „Policies“.
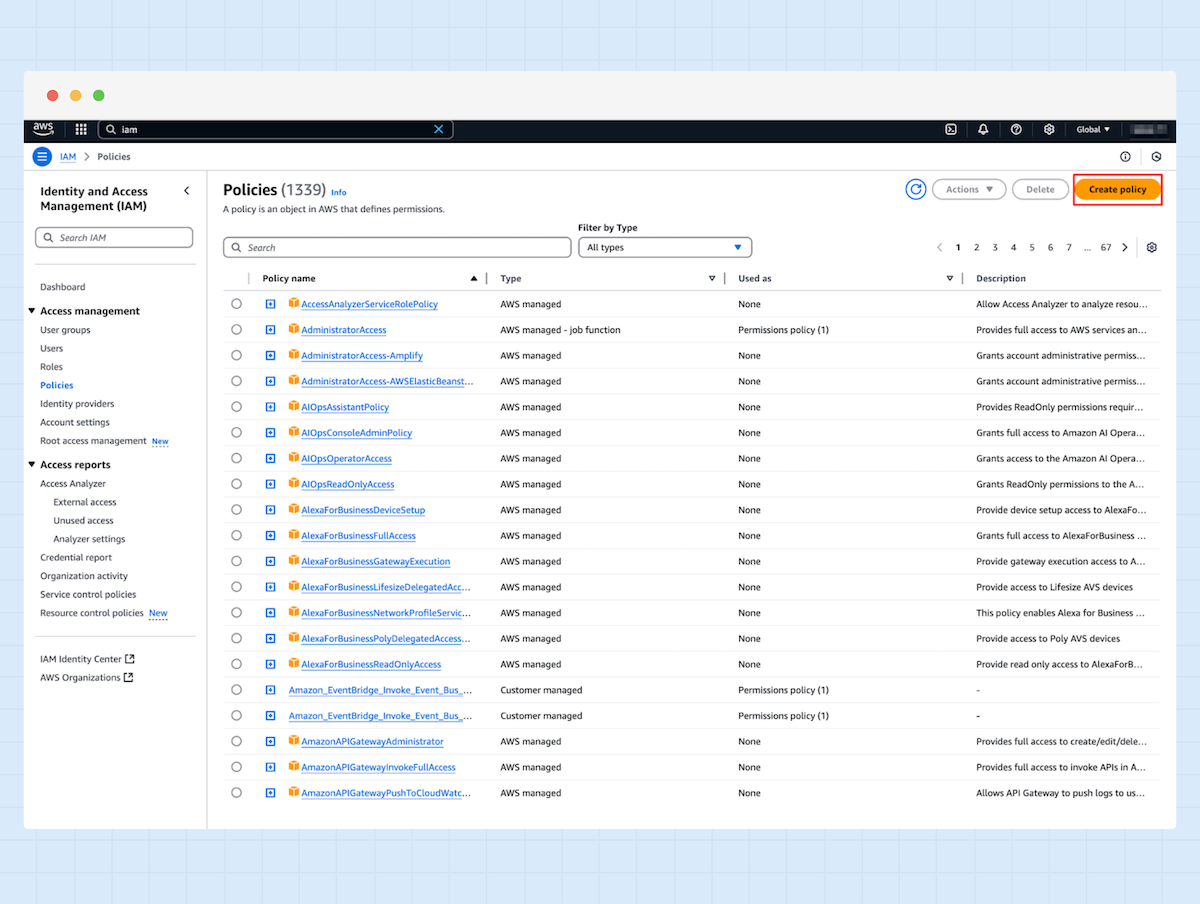
2. Klicken Sie oben rechts auf „Create policy“.
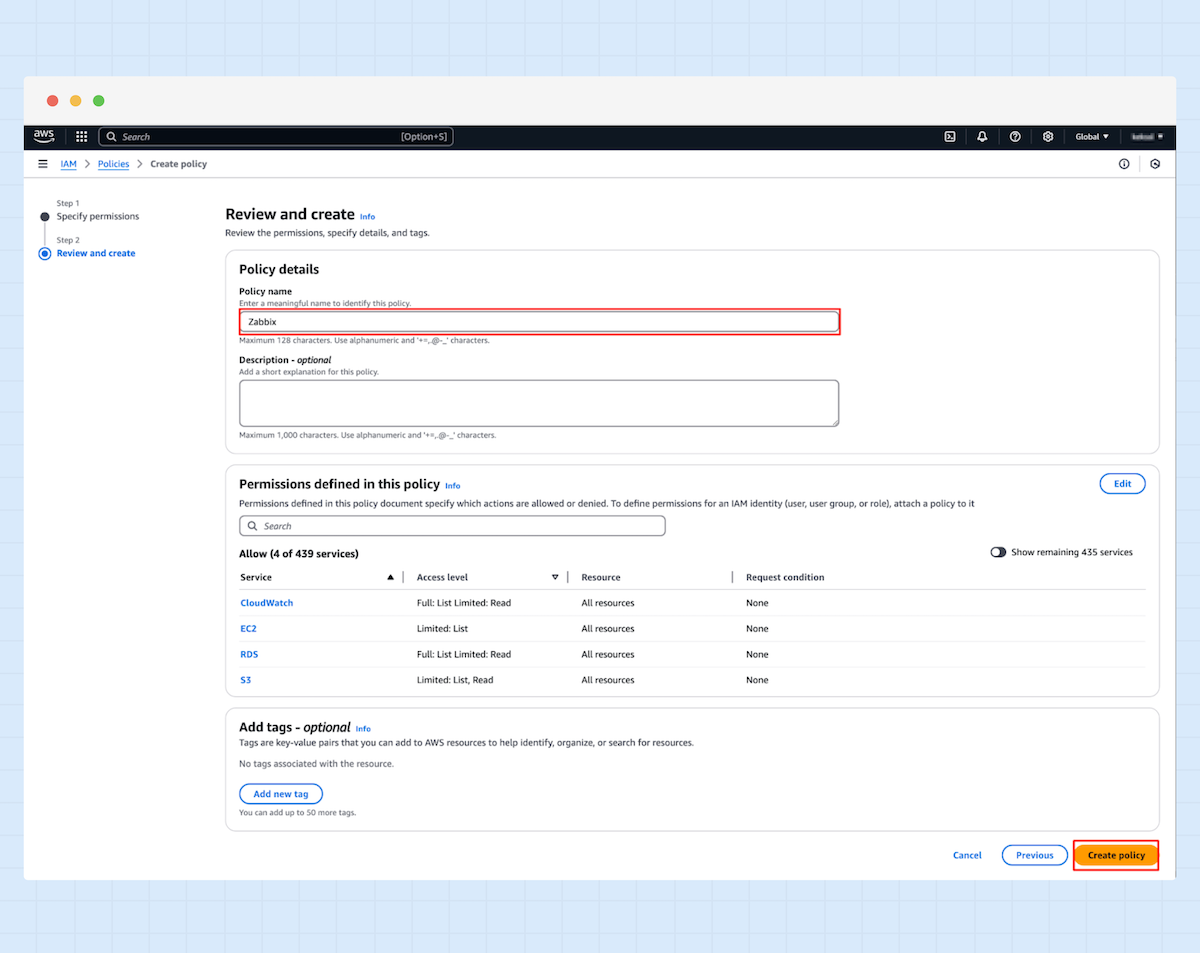
3. Wählen Sie „JSON“ aus und fügen die folgende Konfiguration in den Policy-Editor ein.
4. Geben Sie einen neuen Namen für die Richtlinie ein und klicken Sie auf „Create policy“.
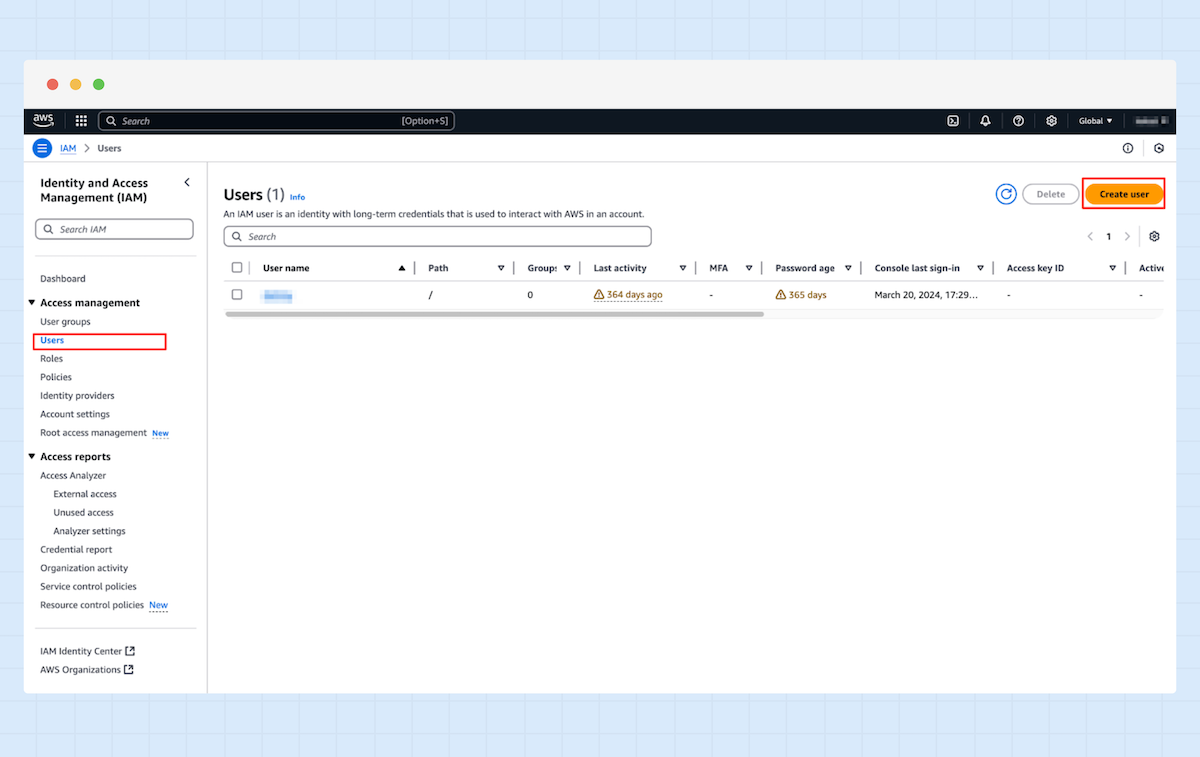
5. Navigieren Sie nun zu „Users“ und klicken Sie auf „Create user“.
6. Geben Sie einen Benutzernamen ein und klicken Sie anschließend auf „Next“.
7. Wählen Sie unter den Berechtigungsoptionen „Attach policies directly“ und markieren die zuvor erstellte Zabbix-Policy.
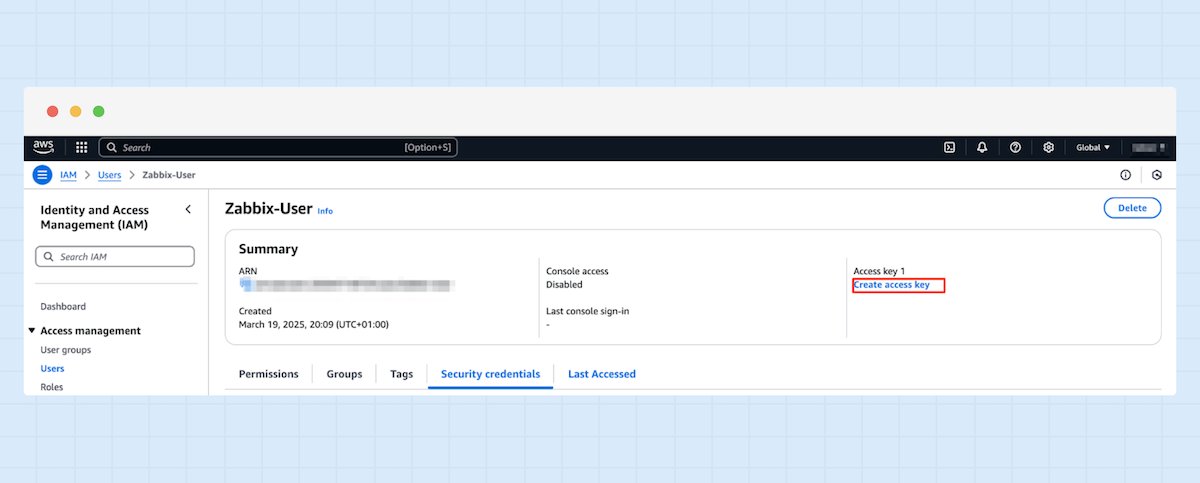
8. Navigieren Sie zum erstellten Benutzer und generieren Sie einen neuen Access Key.
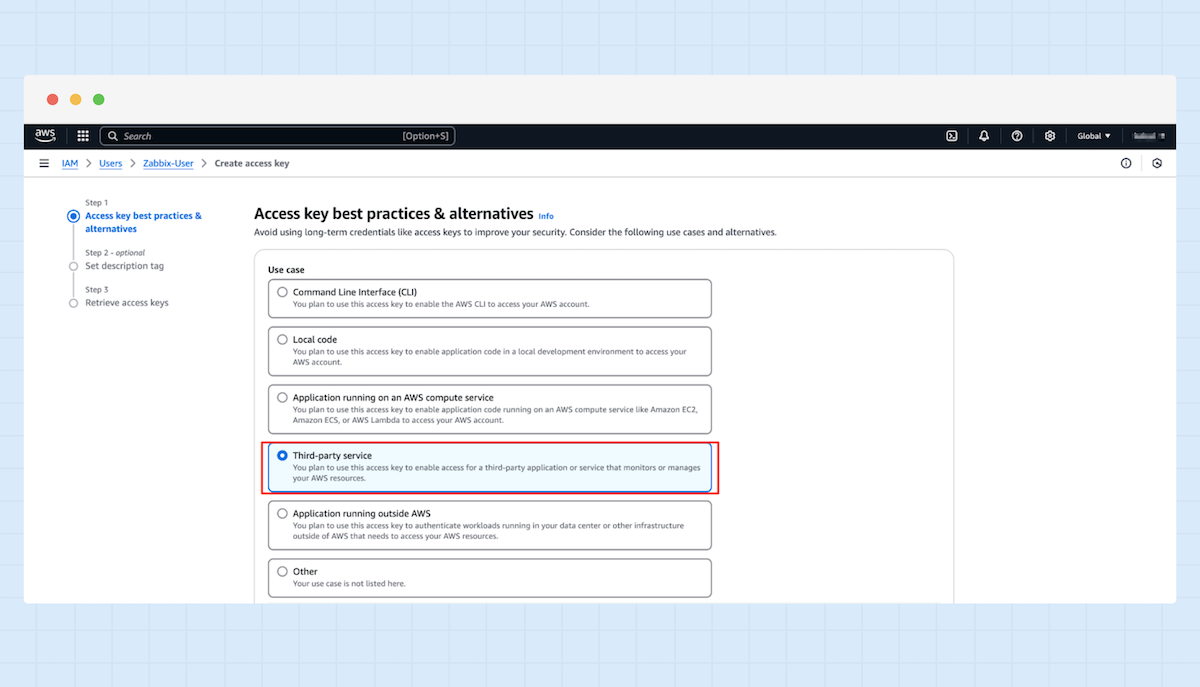
9. Wählen Sie „Third-party service“ aus.
10. Ein Access Key und ein Secret Access Key wurden generiert – diese benötigen Sie später in Ihrer Zabbix-Konfiguration.
Teil 2: Erstellen eines AWS Discovery Hosts in Zabbix Cloud
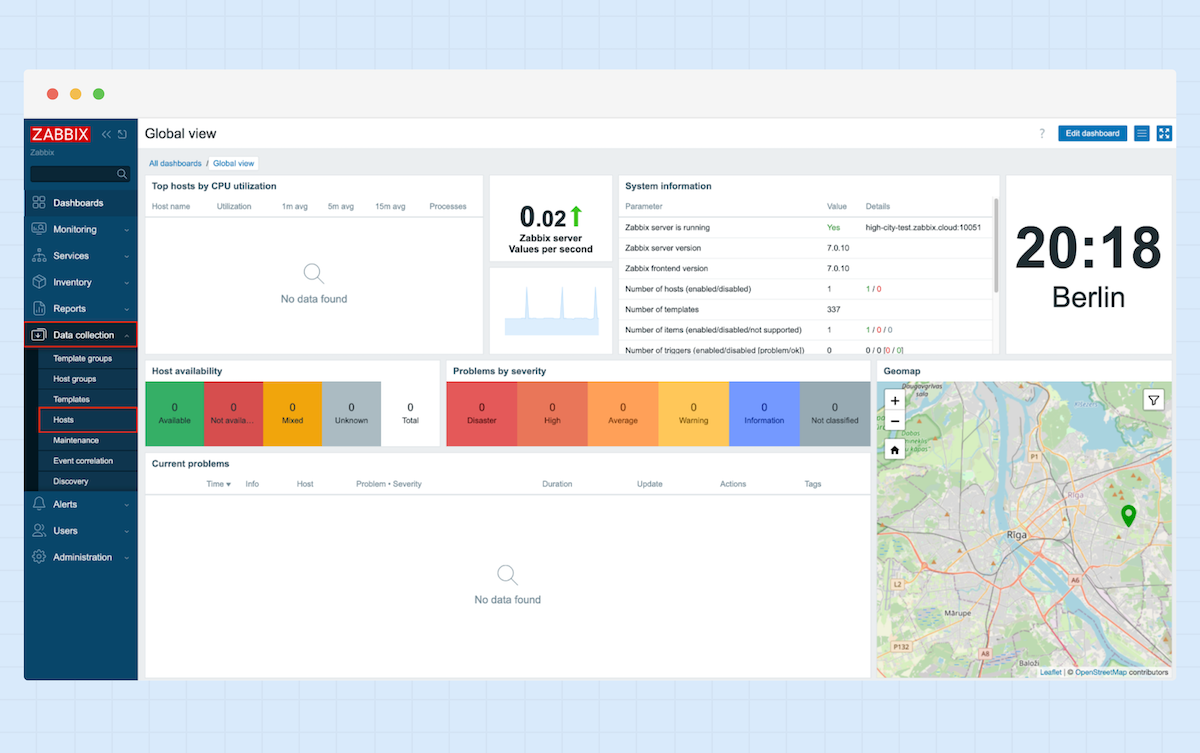
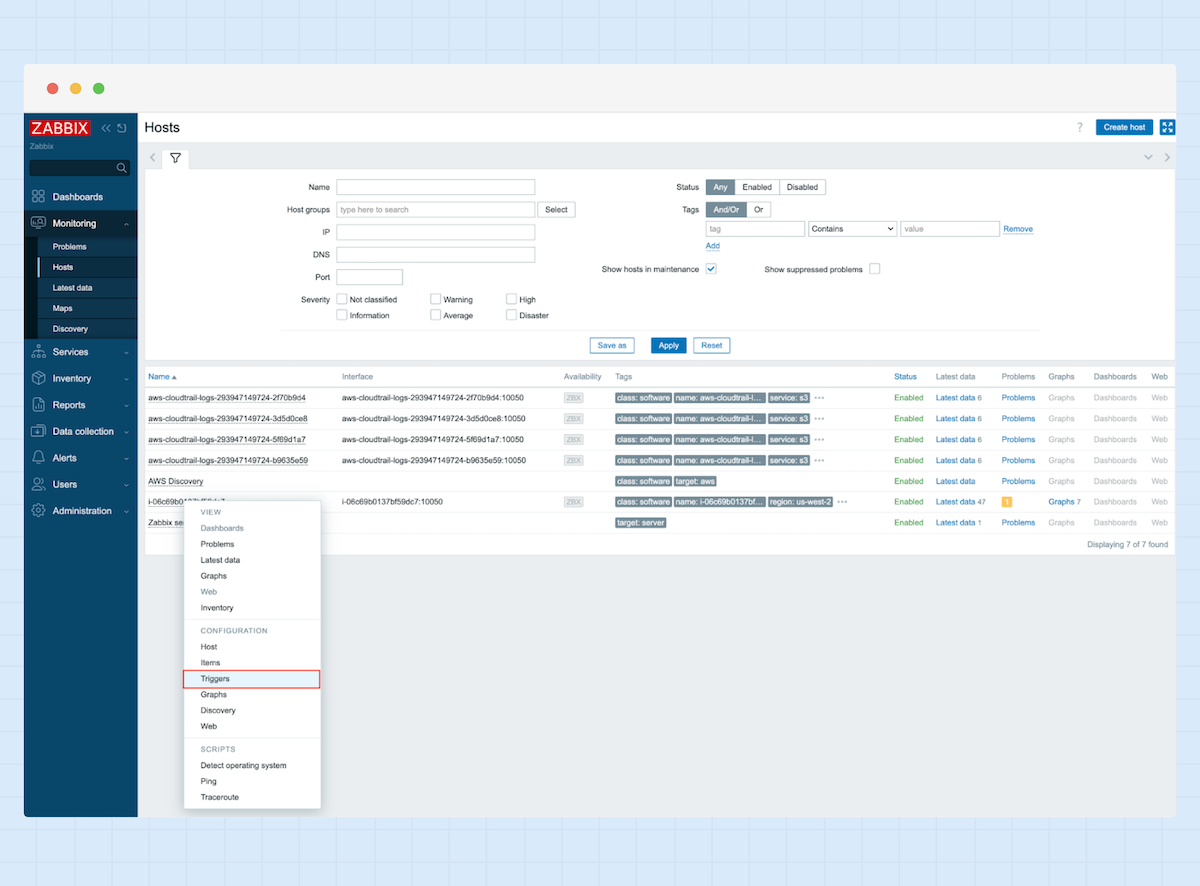
1. Navigieren Sie in der Seitenleiste zu „Data Collection“ und wählen Sie „Hosts“ aus.
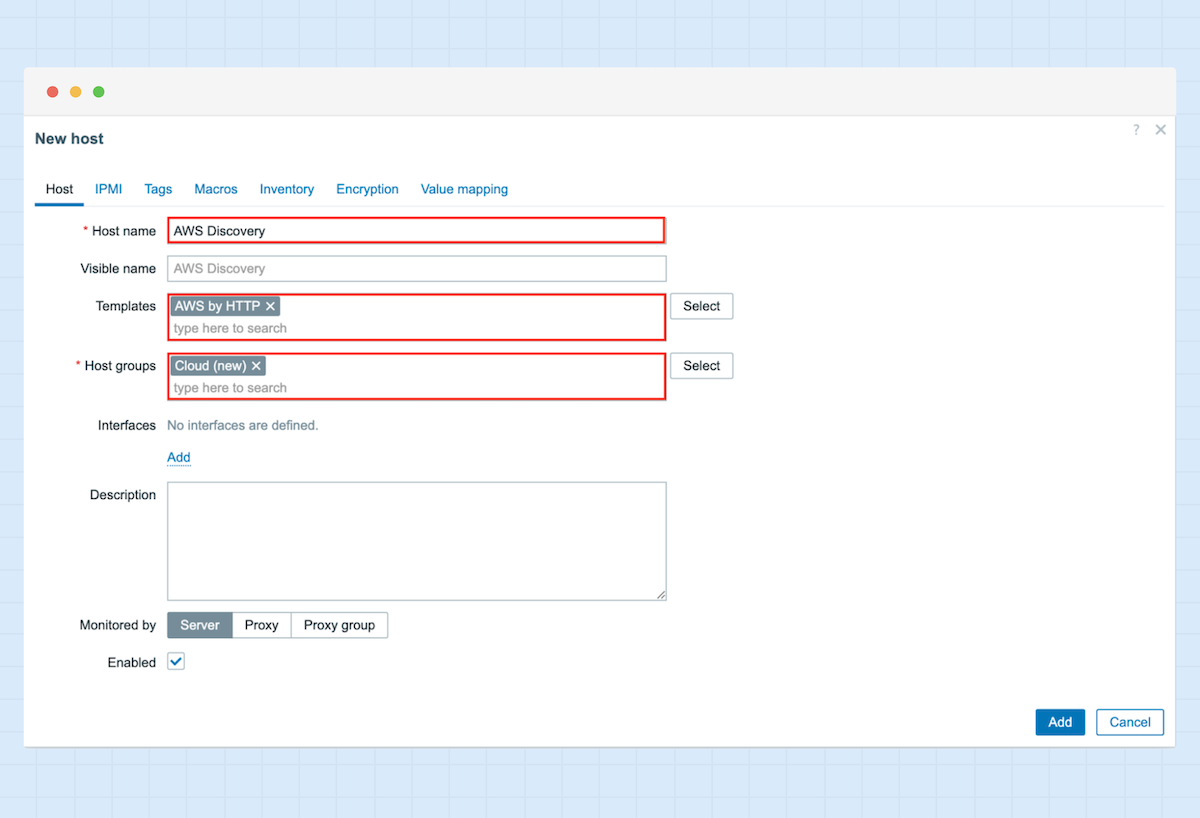
2. Geben Sie einen Namen für Ihren Host ein, wählen Sie als Vorlage „AWS by HTTP“, fügen Sie eine Host-Gruppe hinzu und klicken Sie auf „Add“.
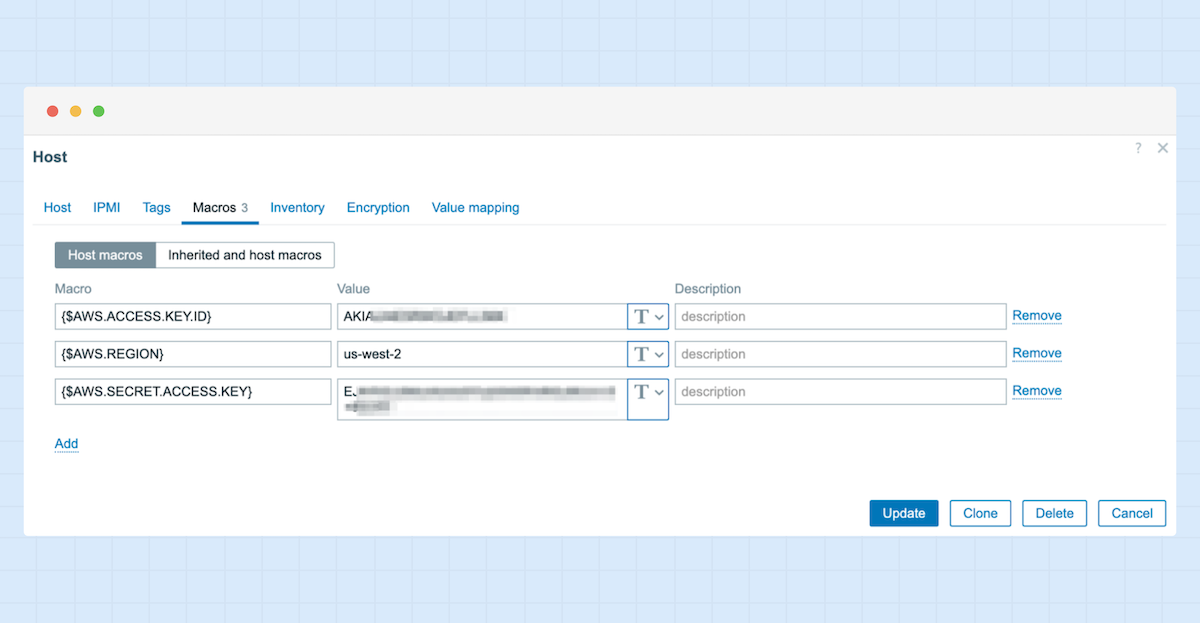
3. Klicken Sie nun auf den neu erstellten Host und navigieren Sie zu „Macros“. Fügen Sie die folgenden Makros hinzu: {$AWS.ACCESS.KEY.ID} {$AWS.REGION} {$AWS.SECRET.ACCESS.KEY} – und tragen Sie die entsprechenden Werte für den Access Key, die Region und den Secret Access Key ein.
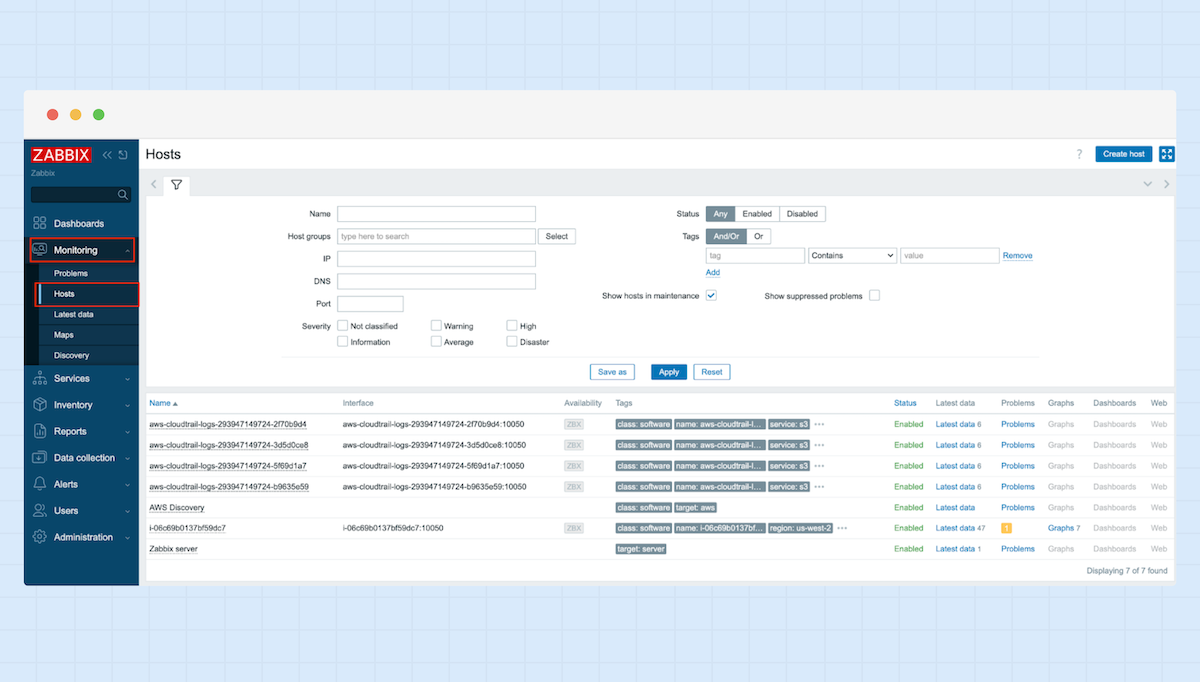
4. Wechseln Sie erneut zum Reiter „Monitoring“ und öffnen Sie dort den Bereich „Hosts“ – Sie sollten nun Ihre Hosts sehen können.
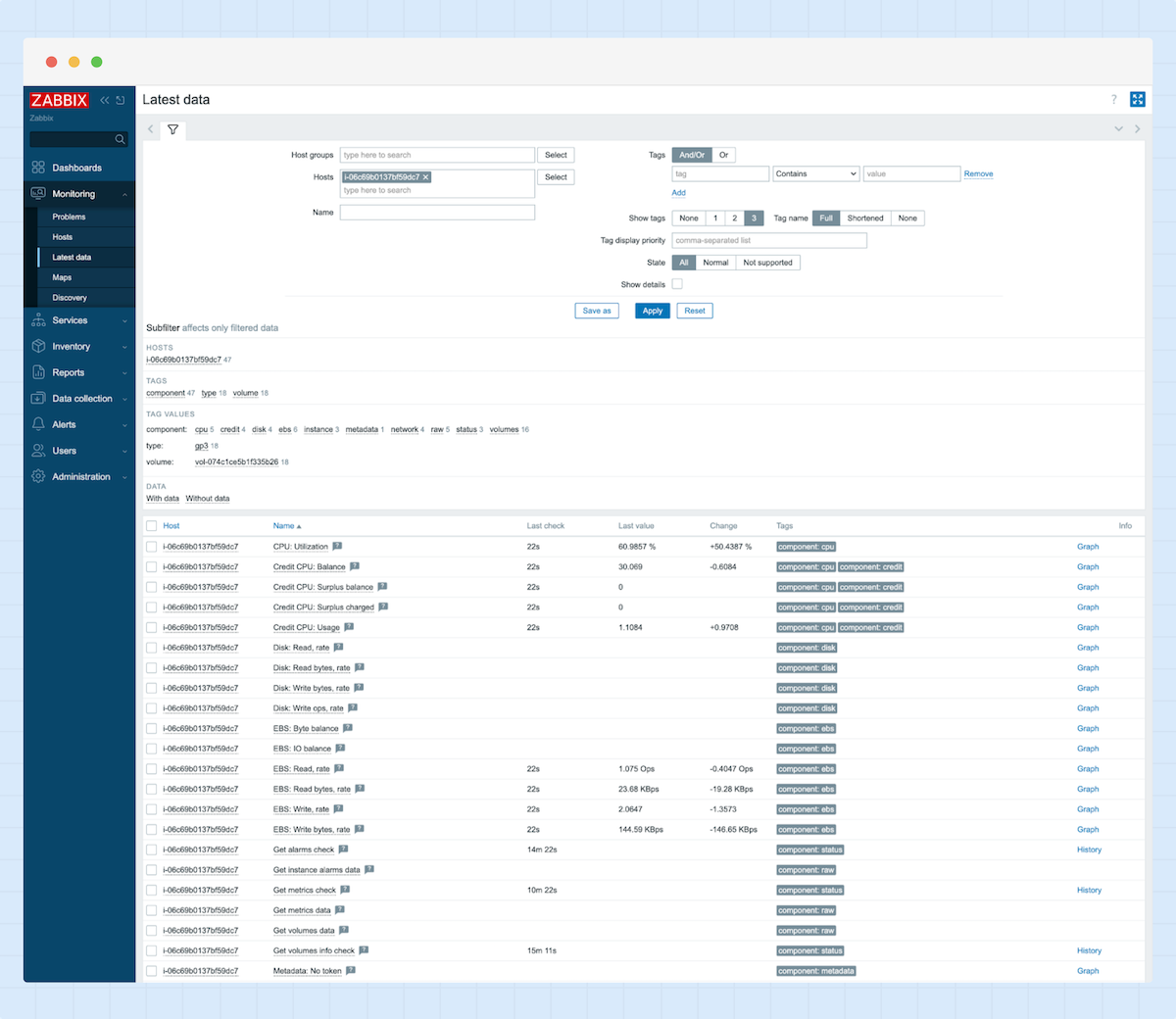
5. Durch einen Klick auf „Latest Data“ können Sie nun alle aktuellen Daten einsehen, die von Ihrer AWS EC2-Instanz empfangen wurden.
Zabbix Dashboards
Zabbix Dashboards bieten eine benutzerfreundliche Oberfläche zur Überwachung Ihrer Infrastruktur – einschließlich Cloud-Umgebungen. Diese ermöglichen einen umfassenden Überblick über zentrale Kennzahlen an einem Ort, darunter Datenbank-Performance, Speichernutzung, Serverzustand und Cloud-Ressourcen.
Mit den Zabbix Dashboards für Infrastruktur- und Cloud-Monitoring behalten Sie Ihre Ressourcen besonders effizient im Blick. Zu den wichtigsten Funktionen der Dashboards gehören:
Anpassbare Layouts
Echtzeit-Monitoring
Verschiedene Widget-Typen (Grafiken, Verfügbarkeiten, Statusanzeigen, Karten usw.)
Monitoring-Dashboards konfigurieren
Nachdem Sie die Auto-Discovery für AWS-Ressourcen eingerichtet und Ihre AWS-Umgebung in das Zabbix Cloud Monitoring integriert haben, können Sie Monitoring-Dashboards erstellen, um vollständige Einblicke in Ihre Cloud-Architektur zu erhalten.
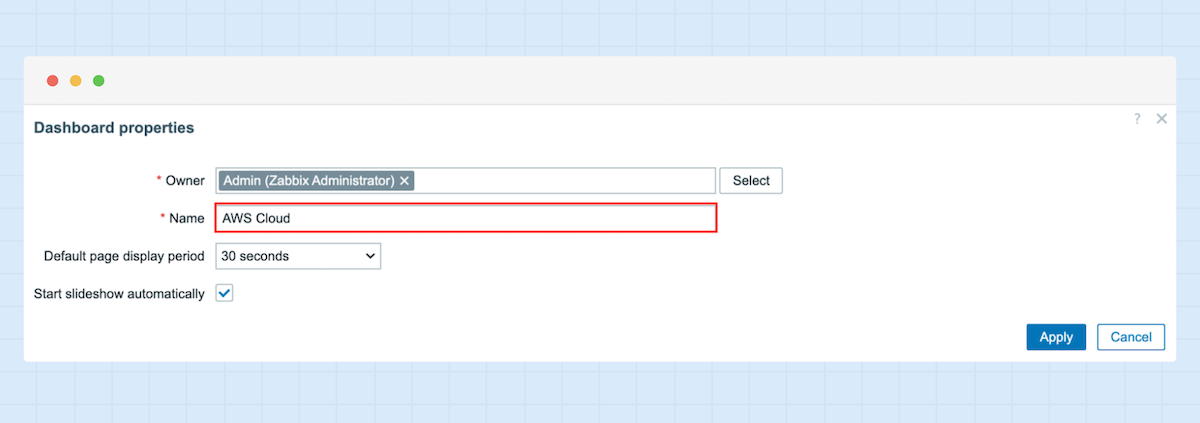
1. Navigieren Sie zu „Dashboards“ und klicken Sie auf „Createdashboard“.
2. Geben Sie einen Namen ein und wählen Sie den Besitzer des neuen Dashboards aus.
3. Sie können nun verschiedene Widgets wie Grafiken, Karten, Diagramme, Verfügbarkeitsstatus und mehr zu Ihrem Dashboard hinzufügen.
Triggers und Media Types in Zabbix Cloud
Trigger und Media Types sind entscheidend für ein proaktives Monitoring. Sie ermöglichen es, Probleme in Ihrer Cloud-Infrastruktur – wie hohe CPU-Auslastung, geringer Speicherplatz oder Dienstunterbrechungen – automatisch zu erkennen und Sie rechtzeitig zu benachrichtigen, wenn es wirklich wichtig ist.
Was sind Trigger?
Trigger in Zabbix sind Ausdrücke, die die von überwachten Elementen gesammelten Daten (z. B. CPU-Auslastung, Speichernutzung, Festplattenplatz usw.) auswerten. Sobald ein vordefinierter Schwellenwert erreicht oder überschritten wird, wird der Trigger ausgelöst.
Beispiele für Trigger:
Festplattennutzung: Ein weiterer Trigger könnte Sie benachrichtigen, wenn die Festplattennutzung einer EC2-Instanz 90 % überschreitet.
CPU-Auslastung: Ein Trigger könnte so eingerichtet werden, dass er warnt, wenn die CPU-Auslastung einer EC2-Instanz für mehr als 5 Minuten über 85 % liegt.
Trigger konfigurieren
1. Navigieren Sie zu „Monitoring“ und dann zu „Hosts“.
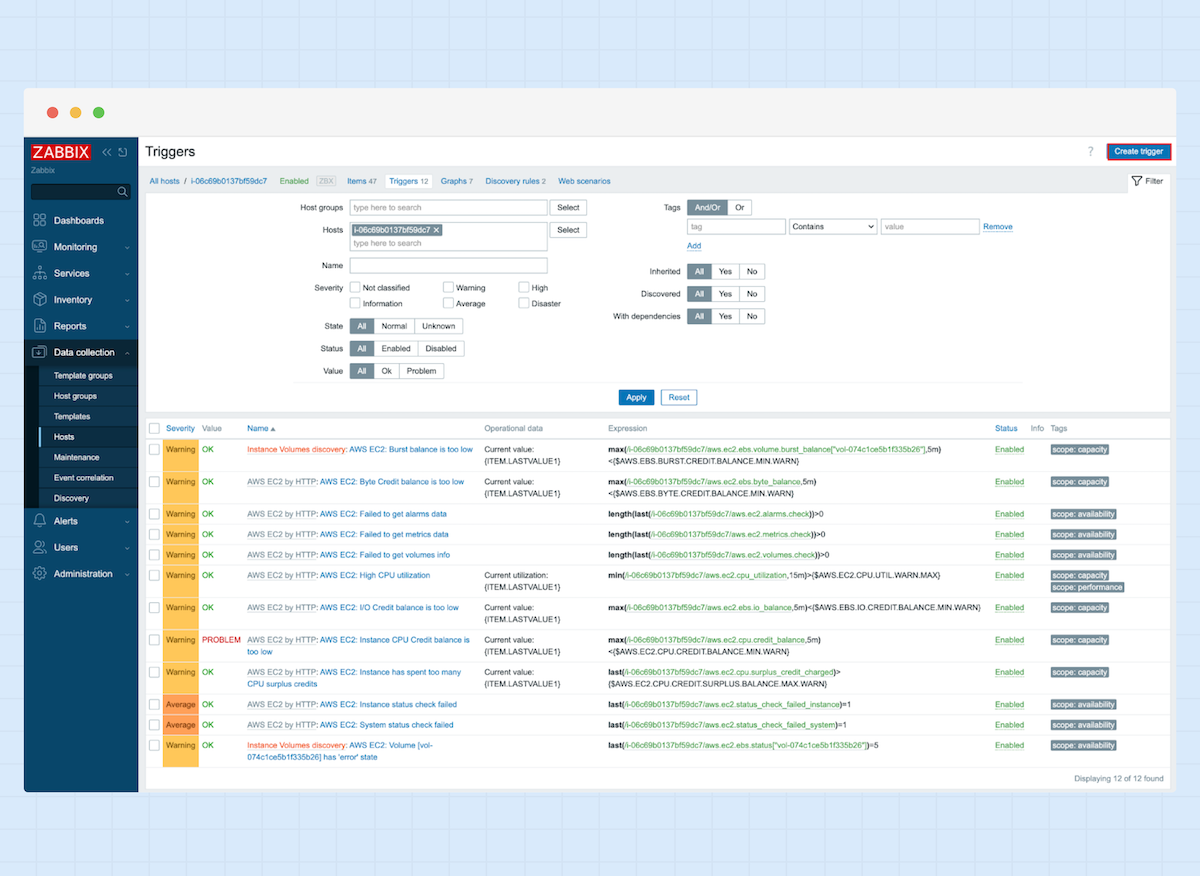
2. Wählen Sie den Host aus, für den Sie einen Trigger erstellen möchten, und klicken Sie unter dem Abschnitt „Configuration“ auf „Triggers“.
3. Klicken Sie nun auf „Createtrigger“.
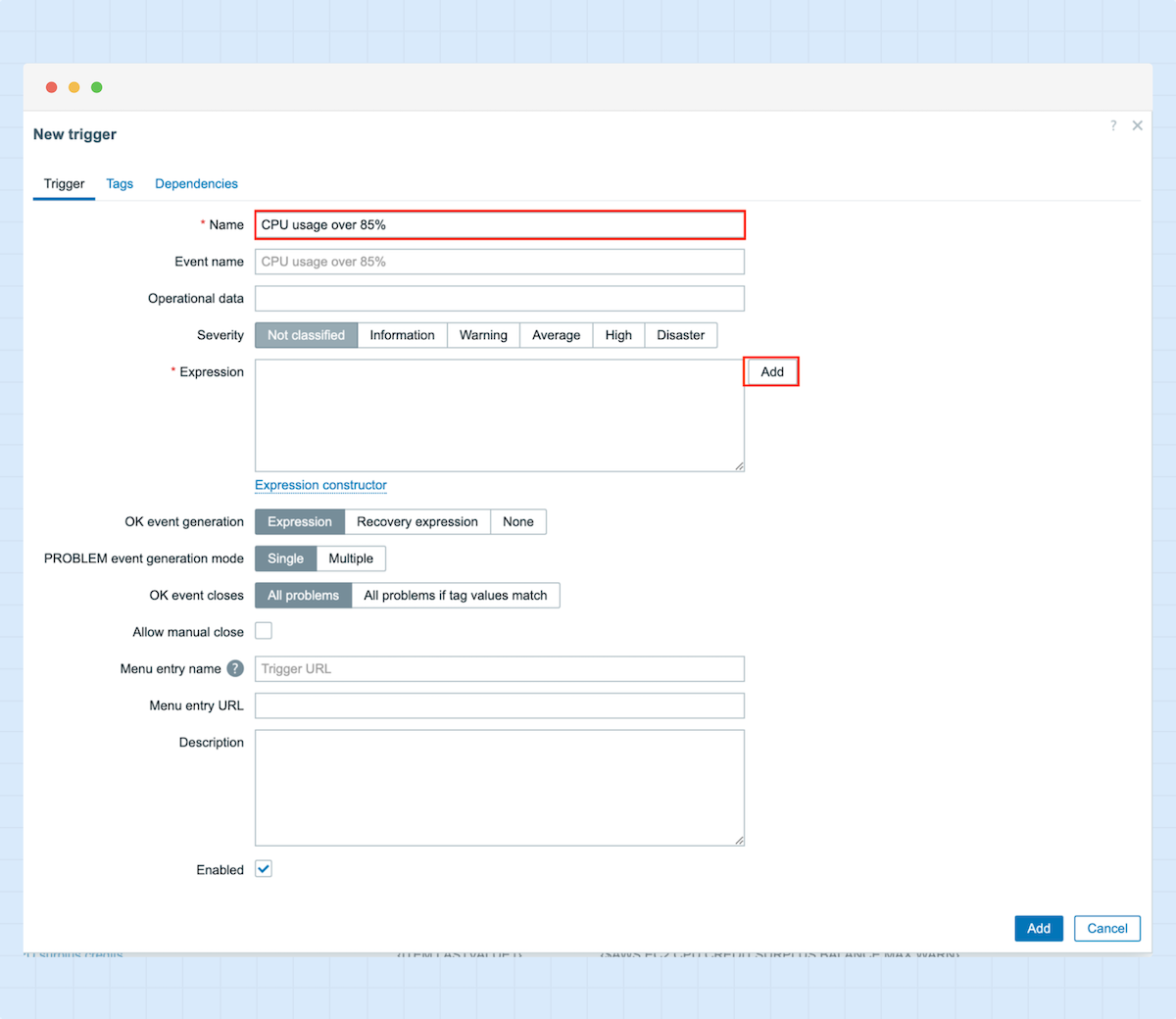
4. In diesem Beispiel konfiguriere ich einen Trigger für die CPU-Auslastung.
5. Nachdem Sie den Namen des Triggers eingegeben haben, können Sie nun den Ausdruck hinzufügen. In diesem Fall wird die Priorität auf „High“ gesetzt, sobald die CPU-Auslastung 85 % überschreitet, und der Trigger wird zurückgesetzt, wenn die CPU-Auslastung unter 80 % fällt.
Was sind Media Types?
In Zabbix beziehen sich Media Types auf die verschiedenen Möglichkeiten, Benachrichtigungen oder Alarme zu erhalten, wenn ein Trigger ausgelöst wird. Ein Media Type legt fest, wie und über welche Kanäle Zabbix Benachrichtigungen an Benutzer:innen sendet.
Zabbix unterstützt eine Vielzahl von Media Types, sodass Sie die Alarmierung flexibel an Ihre Anforderungen anpassen können. Zu den gängigen Media Types gehören:
E-Mail: Versand von Benachrichtigungen per E-Mail, um auf Probleme aufmerksam zu machen.
SMS: Versand von Textnachrichten (SMS) für mobile Warnmeldungen.
Webhook: Auslösen benutzerdefinierter Aktionen oder Integration mit Drittanbietersystemen über Webhooks.
Drittanbieter-Integrationen: Nutzung externer Dienste oder Plattformen – wie z. B. ilert – um Alarme an bestimmte Teams oder Anwendungen weiterzuleiten und so eine reibungslose Integration in Ihre bestehenden Incident-Management-Prozesse sicherzustellen.
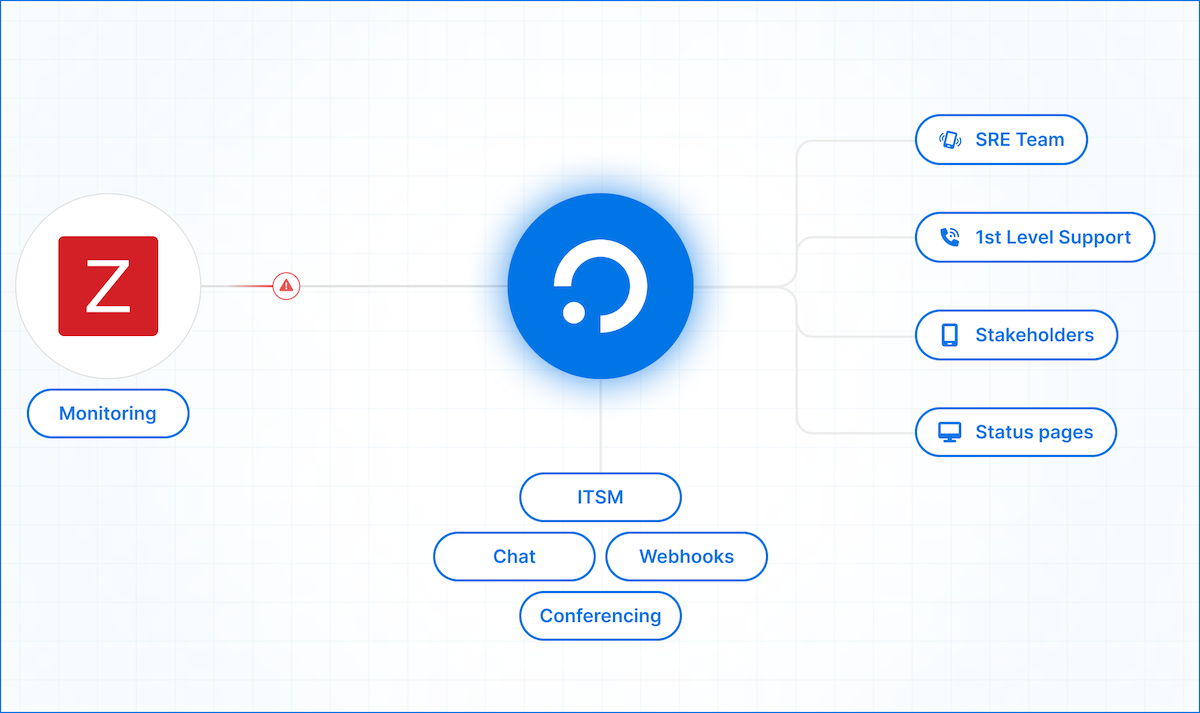
Teil 3: Zabbix mit ilert über dem ilert Media Type verbinden
Um Zabbix mit ilert zu verbinden, erstellen Sie einen neuen Benutzer in Zabbix und fügen Sie ilert als Media Type hinzu. Tragen Sie den Integrationsschlüssel Ihrer Zabbix-Alertquelle in das Feld Send to ein.
In diesem Artikel teilen wir die strukturierte Checkliste, die wir bei ilert verwenden, um die Performance unserer PWA zu messen und zu optimieren.
Bei ilert entwickeln wir unsere Progressive Web App (PWA) mit Capacitor, Ionic, React und MUI, um eine leistungsstarke und reaktionsschnelle Plattform für das Incident-Management bereitzustellen. Progressive Web Apps revolutionieren das Web-Erlebnis, indem sie die besten Eigenschaften von Web- und mobilen Apps kombinieren. Sie bieten schnelle, native-ähnliche Erlebnisse, Offline-Funktionalität und vieles mehr.
Eine hohe Performance ist entscheidend, um den Nutzern eine reibungslose und ansprechende Erfahrung zu bieten.
Was sind Progressive Web Apps?
Falls Sie bereits Erfahrung mit Progressive Web Apps haben, können Sie dieses Kapitel überspringen.
Progressive Web Apps (PWAs) sind eine Art von Webanwendung, die den Nutzern ein native-ähnliches App-Erlebnis bietet. Sie werden mit Web-Technologien wie HTML, CSS und JavaScript entwickelt und sind so konzipiert, dass sie nahtlos auf verschiedenen Plattformen und Geräten funktionieren.
Eine der herausragenden Eigenschaften von PWAs ist ihre Fähigkeit, auch bei schlechter Internetverbindung eine flüssige und ansprechende Nutzererfahrung zu gewährleisten. Im Gegensatz zu herkömmlichen Websites können PWAs auf dem Gerät eines Nutzers installiert werden, was Offline-Zugriff und Push-Benachrichtigungen ermöglicht. Nutzer können also weiterhin mit der App interagieren, selbst wenn sie nicht mit dem Internet verbunden sind.
Darüber hinaus sind PWAs im Gegensatz zu nativen Apps nicht an eine spezifische Plattform gebunden und benötigen keinen separaten Code für jede Plattform. Dadurch sind sie eine vielseitige und kosteneffiziente Lösung für Entwickler.
PWAs bieten eine Reihe von Funktionen, die sie von herkömmlichen Webanwendungen und nativen Apps unterscheiden:
Offline-Funktionalität: Dank Caching und Service Workern können PWAs auch ohne Internetverbindung oder bei schwacher Verbindung funktionieren. So haben Nutzer jederzeit Zugriff auf wichtige Inhalte und Funktionen.
Installierbarkeit: PWAs können auf einem Gerät installiert werden und bieten dadurch Offline-Zugriff sowie die Möglichkeit, Push-Benachrichtigungen zu senden.
Individuelle Offline-Seite: Wenn Nutzer offline sind, kann eine individuelle Offline-Seite angezeigt werden, die hilfreiche Informationen oder alternative Aktionen bietet.
Push-Benachrichtigungen: PWAs können Push-Benachrichtigungen senden, um Nutzer zu informieren und zu reaktivieren, auch wenn die App nicht geöffnet ist.
App-Window: PWAs können in einem eigenen App-Fenster angezeigt werden, wodurch sie sich wie eine native App in das Betriebssystem des Geräts integrieren.
Warum Performance bei Progressive Web Apps wichtig ist
Die Performance einer PWA hat direkten Einfluss auf die Nutzererfahrung. Nutzer empfinden die Geschwindigkeit und Reaktionsfähigkeit einer PWA als essenziell für ihr gesamtes Erlebnis. Eine schnell ladende und reaktionsschnelle PWA führt dazu, dass Nutzer bleiben, interagieren und die Funktionen effektiv nutzen.
Eine der wichtigsten Metriken zur Leistungsbewertung ist die Time to Interactive (TTI). Sie misst die Zeit, die eine PWA benötigt, um vollständig interaktiv zu sein.
Ein TTI unter 3,8 Sekunden gilt als schnell und sorgt für ein reibungsloses Nutzererlebnis.
Ein TTI zwischen 3,9 und 7,3 Sekunden bedeutet eine mittelmäßige Performance, die verbessert werden sollte.
Alles über 7,3 Sekunden wird als langsam eingestuft und kann Frustration sowie eine hohe Absprungrate verursachen.
Measuring PWA performance
Before optimizing your PWA, it’s essential to establish a baseline by measuring current performance. Here are some effective ways to evaluate your PWA’s speed and responsiveness:
Browser developer tools: Inspect loading times and resource usage in Chrome DevTools.
Manual testing: Just clicking through the app can actually reveal a lot of performance issues and bad UX. Doing this after developing a new feature can bring significant insights for optimization.
At ilert, manual testing is an important part of our performance evaluation. Whenever we develop a new feature, we actively test it by navigating through the app, identifying potential performance issues, and ensuring a smooth user experience. Manual testing also helps to identify performance issues that automated tools might miss.
Following our performance checklist, we can proactively address issues before they impact our users.
Checklist: Improving PWA performance
1. Optimize bundle sizes
Reduce bundle sizes: Remove unused code and load images from a CDN to minimize bundle sizes.
Implement code splitting: Only load the necessary scripts and components that are required for the current page.
2. Implement Lazy Loading
Don't load images and content until they are needed.
Use skeletons wisely: Avoid excessive placeholders that may cause unnecessary lag.
3. Minimize artificial loading times
Eliminate unnecessary delays: Review intentional load times to ensure they are essential for UX.
4. Optimize app size
Trim audio files: Reduce unnecessary sound assets or cut them shorter.
Ensure a fast backend: Reduce API response times through efficient backend design and optimized queries.
We are actively making incremental improvements with our PWA. Small changes such as optimizing skeleton loaders, reducing JavaScript bundle sizes, and ensuring a fast backend have significantly reduced load times and improved our time to interactive (TTI). Feel free to copy the checklist from the article and use it when reviewing your PWA next time.
Die kürzliche Ankündigung von Atlassian, dass der Verkauf von Opsgenie im Sommer 2025 eingestellt und der Dienst 2027 abgeschaltet wird, kam für uns nicht wirklich überraschend. Bereits zuvor haben wir von neuen Kunden, die sich für ilert statt Opsgenie entschieden hatten, gehört, dass sich die Atlassian-Plattform seit einiger Zeit nicht mehr weiterentwickelt hat. Was uns jedoch wirklich erstaunt hat, waren die Alternativen, die Atlassian bestehenden Opsgenie-Nutzern anbietet.
Wir haben uns daher entschieden, diese Erklärung zu schreiben, um Nutzern eine fundierte Entscheidung zu ermöglichen und einen smarten Wechsel zu erleichtern. Für alle Opsgenie-Nutzer, die eine Migration in Betracht ziehen, bieten wir zusätzliche Demos und Unterstützung an, um den Prozess zu vereinfachen. Füllen Sie einfach das Formular unter diesem Artikel aus, und wir setzen uns mit Ihnen in Verbindung!
Vereinbaren Sie eine Beratung zur Migration von Opsgenie
Jira Service Management vs. Echtzeit-Incident-Management
Zunächst einmal sehen wir in dieser Situation zwar eine Chance, aber das Ende von Opsgenie ist dennoch eine traurige Nachricht.
Das Unternehmen zählte zu den Pionieren im Bereich Incident-Management-Plattformen. Opsgenie war ein echtes Schwergewicht, und es ist bedauerlich zu sehen, dass jahrelange Entwicklungsarbeit bald eingestellt wird.
Atlassian bietet Opsgenie-Nutzern nun zwei Alternativen an: Jira Service Management (JSM) und Compass. Keine dieser beiden Lösungen erfüllt jedoch die Anforderungen an einen zentralen Alert-Dispatcher und ein vollwertiges Incident-Management. Beide decken spezifische Anwendungsfälle ab, weisen aber Lücken im Vergleich zu Opsgenie auf.
Schauen wir uns die Alternativen im Detail an:
Jira Service Management (JSM) ist Atlassians ITSM-Lösung. Sie bietet zwar einige Incident-Response-Funktionen, ist jedoch in erster Linie ein Ticketing-System, das für IT-Support-Teams und nicht für Engineering- und On-Call-Teams entwickelt wurde.
Mehr zu den wesentlichen Unterschieden zwischen Echtzeit-Incident-Management-Plattformen und ITSM erfahren Sie in unserem Buyer’s Guide (auf Englisch).
JSM bietet Funktionen wie Anfragen-, Änderungs- und Asset-Management, die für strukturierte IT-Workflows nützlich sind. Einige Opsgenie-Funktionen, wie Alarmierung und Eskalationen, wurden integriert. Allerdings ersetzt das nicht eine vollständige Incident-Management-Lösung, die als zentraler Knotenpunkt für alle kritischen Ereignisse dient und Teams in jeder Phase eines Incidents begleitet. Zum Beispiel müssen JSM-Nutzer für Statusseiten auf eine separate Lösung wie Atlassian Status Pages zurückgreifen.
Zudem sind die Tarife von JSM deutlich anspruchsvoller, insbesondere für kleine Teams, die erst mit ihrem Incident-Management starten.
Wie sieht es mit Compass aus, der zweiten Option, die Atlassian Opsgenie-Kunden anbietet? Kann Compass die Lücke, die JSM hinterlässt, füllen? Schauen wir es uns an.
Compass – ein Entwicklerportal, aber keine Incident-Management-Lösung
Compass ist Atlassians zweite Alternative für Opsgenie-Nutzer, aber es als Ersatz zu bezeichnen, ist weit hergeholt. Im Gegensatz zu JSM, das auf ITSM-Workflows fokussiert ist, ist Compass ein Entwicklerportal, das Teams hilft, Softwarekomponenten, Abhängigkeiten und den Gesundheitszustand ihrer Services zu verwalten.
Im Kern soll Compass die Software-Sichtbarkeit und Zusammenarbeit verbessern. Es bietet Teams eine zentrale Plattform zur Dokumentation von Service-Verantwortlichkeiten, zur Überwachung der Service-Performance und zur Etablierung von Best Practices für Microservices. Dies ist zwar nützlich, um die langfristigen Betriebskosten zu senken und die Entwicklererfahrung zu verbessern, bietet jedoch keine entscheidenden Tools für ein ordnungsgemäßes Incident-Management und eine angemessene Kommunikation.
Die Lösung bietet zwar Integrationen von Observability-Tools, um Einblicke in die Service-Zuverlässigkeit zu liefern, bietet jedoch keine automatisierten Workflows, um auf diese zu reagieren. Es gibt keine Möglichkeit, sicherzustellen, dass Alarmierungen die richtigen Techniker zur richtigen Zeit erreichen, keine umfassende und anpassbare Anrufweiterleitung, um Störungen nicht zu übersehen, und keine Stakeholder-Rollen für gezielte Kommunikation. Zudem wird die europäische Region nicht unterstützt – Compass ist nur in den USA verfügbar.
Eine detaillierte Liste der fehlenden Funktionen finden Sie in der offiziellen Atlassian-Dokumentation unter "Deprecated features in Compass". Kurz gesagt: Compass ist ein großartiges Tool zur langfristigen Softwarepflege, aber es löst nicht die akuten Bedürfnisse von On-Call-Teams.
Was bedeutet das konkret für Opsgenie-Kunden, die eine echte Incident-Management-Lösung suchen?
Hier kommt ilert ins Spiel.
Why ilert is the best Opsgenie alternative
Wenn Sie Opsgenie-Nutzer sind und nach einem echten Ersatz suchen, werden weder Jira Service Management noch Compass Ihre Anforderungen vollständig erfüllen – ilert aber schon.
Im Gegensatz zu den von Atlassian angebotenen Alternativen wurde ilert speziell für Incident Response entwickelt – nicht nur für ITSM-Workflows oder Entwicklerdokumentation. Es kombiniert On-Call-Planung, Alarmierung und Incident-Management, um sicherzustellen, dass kein kritisches Problem übersehen wird.
Leistungsstarkes On-Call-Management: ilert bietet flexible Bereitschaftspläne, Eskalationsrichtlinien und Ausnahmeregelungen, die sicherstellen, dass Alarmierungen immer die richtige Person zur richtigen Zeit erreichen.
Multi-Channel-Alarmierung: Ob Anrufe, SMS, Push-Benachrichtigungen oder Messenger – ilert alarmiert Teams sofort und zuverlässig.
Umfassende Integrationen: ilert integriert sich nahtlos in Ihre bestehenden Monitoring-, Observability-, Automatisierungs- und ITSM-Tools wie AWS, Datadog, Prometheus, ServiceNow und (ja) Jira.
ChatOps ohne Zusatzkosten: Wir sind überzeugt, dass ChatOps ein fester Bestandteil des Incident-Managements ist und erheben deshalb keine zusätzlichen Gebühren dafür.
Eingebaute CI/CD-Pipelines: Echtzeit-Einblick in Ihre Deployment-Ereignisse hilft Ihnen, schnell zu erkennen, ob ein kürzliches Deployment einen Vorfall ausgelöst hat – und spart wertvolle Zeit in kritischen Momenten. ilert integriert sich nativ in die beliebtesten CI/CD-Lösungen.
Das fortschrittlichste Call-Routing auf dem Markt: ilert bietet eine leistungsstarke Hotline für On-Call-Teams, um die Incident-Response zu automatisieren, Beziehungen zu Kunden und Stakeholdern zu pflegen und in Notfällen schnellen Support zu leisten.
Unterstützung für europäische Unternehmen: ilert wird in der EU gehostet, ist DSGVO-konform und bietet niedrige Latenzen sowie regionalen Support.
Und falls Sie sich über unsere Zukunft wundern: Wir bleiben. Die ilert GmbH ist ein deutsches, bootstrapped Unternehmen – motiviert, unabhängig und resilient. Wir nutzen unsere eigene Lösung täglich, um eine Plattformverfügbarkeit von 99,99 % zu gewährleisten. Unsere Kunden kennen uns persönlich, und wir sind stolz darauf, ihnen den Support zu bieten, den sie verdienen.
Unser Fazit
Atlassians Entscheidung, Opsgenie einzustellen, zwingt Teams dazu, ihr Incident-Management neu zu bewerten. Während JSM und Compass andere Anwendungsfälle abdecken, ersetzt keine der beiden Lösungen Opsgenie vollständig.
ilert ist die richtige Wahl für Unternehmen, die eine zukunftssichere Incident-Management-Plattform benötigen. Viele Teams haben den Wechsel bereits vollzogen – wir helfen Ihnen gerne dabei.
Hoppla! Beim Absenden des Formulars ist etwas schief gelaufen.
Unsere Cookie-Richtlinie
Wir verwenden Cookies, um Ihre Erfahrung zu verbessern, den Seitenverkehr zu verbessern und für Marketingzwecke. Erfahren Sie mehr in unserem Datenschutzrichtlinie.


.png)










.png)









































